Is GLM 5.2 Real, or Just This Month's Hype? (And How to Try It in Elyra in 60 Seconds)
GLM 5.2 from Z.ai is all over your timeline. Here's the un-fun version: what's measurable (a 1M context window, the price), what's vibes (leaderboards), and how to run it in Elyra across five providers in about a minute — plus the routing trick that actually beats the hype.
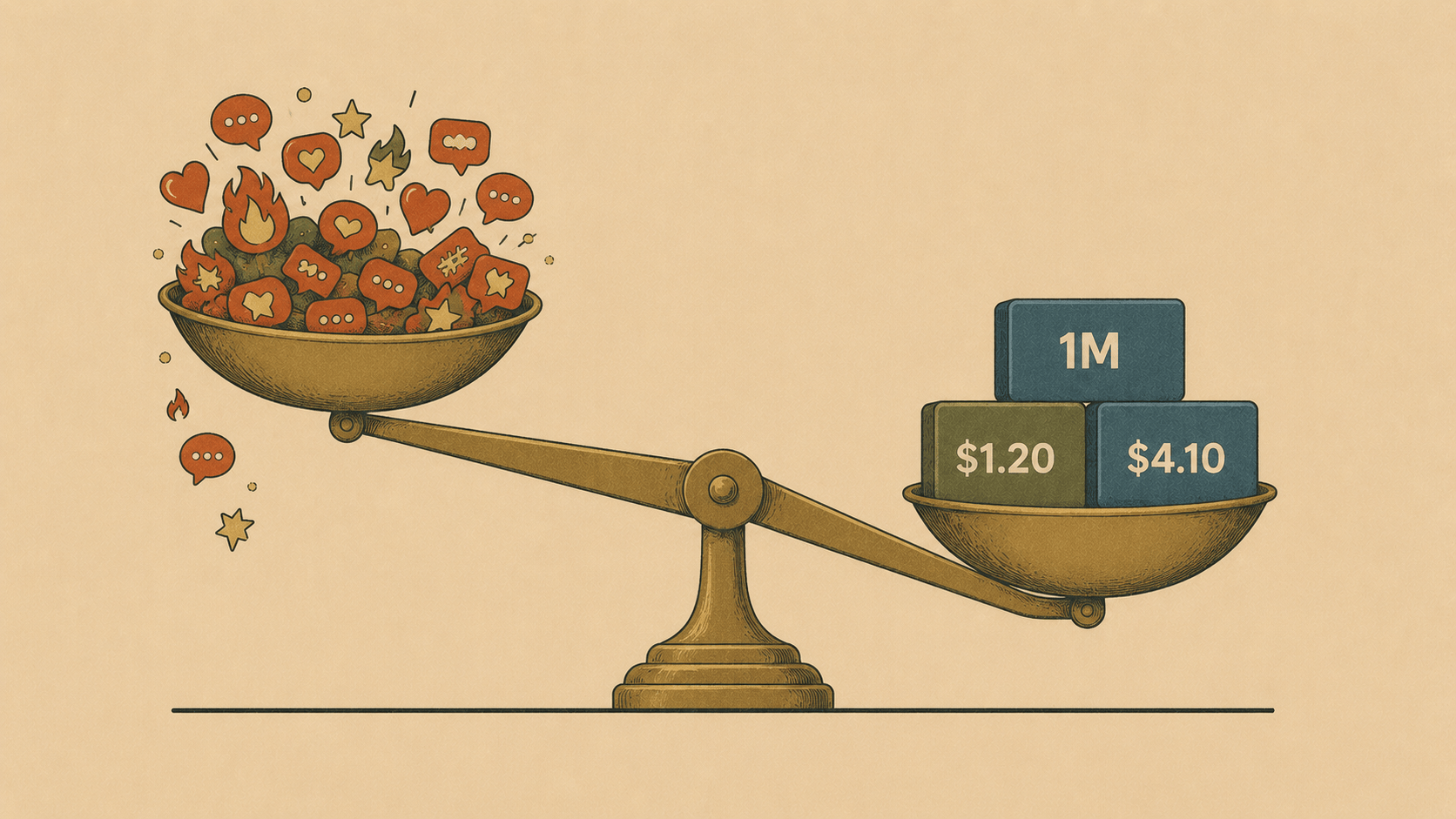
Every few weeks a model takes over your timeline. Right now it's GLM 5.2 from Z.ai (Zhipu). The screenshots look great, the price looks impossible, and everyone suddenly has an opinion. So let's do the un-fun thing and separate what's measurable from what's vibes — and then, if you want to judge for yourself, get it running in Elyra in about a minute.
First, the honest answer
GLM 5.2 is not just hype — but it's also not magic. Both things are true, and the reason is boring: it's a genuinely strong model in a price tier where strong models didn't used to exist. That's enough to earn the attention without needing the "GPT-killer" headlines.
Here's what I can actually stand behind, because it's in front of me rather than on a leaderboard.
What's verifiable
These numbers are straight from Elyra's model registry, not a marketing slide:
GLM 5.1 GLM 5.2 Context window ~203K ~1,048K (1M) Reasoning yes yes Cost (OpenRouter, in/out per 1M) $0.98 / $3.08 $1.20 / $4.10 Cost (Z.ai coding plan) flat flat
Two things jump out:
The context window 5x'd. Going from 203K to a full 1M tokens between 5.1 and 5.2 is the kind of jump that actually changes what you can do — feeding a whole service's worth of files into one session instead of chunking it. This is a real capability change, not a benchmark tweak.
The price is the actual story. At roughly $1.20 in / $4.10 out, GLM 5.2 sits well below the frontier coding models while staying in the same conversation about quality. And if you're on Z.ai's coding plan, it's a flat subscription rather than per-token. That's why your timeline is excited. Not because it dethroned anything — because it's "good enough for most of my real work, at a fraction of the cost."
What's hype (or at least unproven)
Let me be straight about what I won't claim:
Leaderboard rankings. Benchmark charts age in days, are easy to cherry-pick, and rarely match your actual repo. If a thread says "beats [frontier model] on SWE-bench," treat that as a hypothesis, not a result. The only benchmark that matters is your codebase.
"It replaces everything." It doesn't. A cheap, capable model is fantastic for the 80% of work that's mechanical — refactors, tests, boilerplate, exploration. For the gnarliest 20%, you'll still want to reach for a top-tier model. The win isn't replacement; it's routing the cheap work to the cheap model.
The healthy framing: GLM 5.2 lowers the cost floor of "competent." That's valuable precisely because it's unglamorous.
How to actually try it (this is the easy part)
This is where Elyra earns its keep. You don't install an SDK, wire up an endpoint, or read Z.ai's API docs. GLM 5.2 is already in the registry across five providers — pick whichever key you already have.
Option A — Z.ai directly (best if you're on the coding plan; the reasoning format is pre-configured):
export ZAI_API_KEY=your-key
elyra --model zai/glm-5.2
Option B — via OpenRouter (no separate Z.ai account needed):
export OPENROUTER_API_KEY=your-key
elyra --model z-ai/glm-5.2
That's the whole setup. No enable_thinking flag-wrangling, no compatibility shims — Elyra already knows GLM's quirks (it uses Z.ai's enable_thinking reasoning format and supports tool-streaming on 5.2, unlike the older 4.5 line).
The smart move: don't choose, route
Here's the pattern that actually beats the hype. Instead of picking GLM 5.2 or a frontier model, pin GLM 5.2 to your fast/cheap tier and let Elyra's smart routing decide per turn:
// settings
"smartRoutingModels": {
"fast": "zai/glm-5.2",
"balanced": "zai/glm-5.2",
"powerful": "claude-sonnet-4-20250514"
}
Now the mechanical turns — reading files, running greps, writing tests — go to GLM 5.2 at a fraction of the cost, and only the genuinely hard turns escalate. Run /route to preview which tier the next turn will use, and /cost to watch the burn rate drop. That's the version of "GLM 5.2 is amazing" that survives contact with your invoice.
The verdict
GLM 5.2 is worth your sixty seconds — not because it's the best model in the world, but because it's a very good model at a price that changes how you budget a coding session. The 1M context is real. The price is real. The leaderboard war is noise.
Try it on your own repo for an afternoon. Route the boring work to it, keep your favorite frontier model for the hard parts, and check /cost at the end of the day. Let your own numbers decide — that's the only review that isn't hype.